


How HTTP Status Codes & Network Impact Your SEO - Technical SEO Audit
Table of Contents (Click to show/hide)




HTTP status codes, Google bot crawl rate, network issues and DNS errors

Understanding the SEO impact of HTTP status codes, network issues, and DNS errors is a crucial step in a technical SEO audit. Your response code status indicates the initial stage of the browsing experience. What's more, it affects your queue in the Google indexing pipeline, Google bot crawl rate and ultimately your SERP ranking.
Recently, Google released a new guide detailing how these issues impact your Google search performance. This article will look at these often overlooked & ignored issues and provide a step-by-step guide.
First, What is HTTP Status Code?
Quick and straightforward, HTTP status codes is a server response to a specific HTTP request.
When a user enters a URL and clicks "enter", the browser will send an HTTP request to the server asking for CSS, HTML and Javascript content to be sent to the browser. It's like a ship being assigned a pickup route from the client to the server. Once the ship submits the pickup order (the request) to the server, it will load the goods (the response) and carry them back to the browser.
There are five classes of responses that have an SEO impact:
- 2xx codes (Success)
- 3xx codes (Redirection)
- 4xx codes (Client Errors)
- 5xx codes (Server Errors)
Note:Google confirmed that they would start crawling sites over HTTP/2. See how it will impact your SEO.
How to find the problem?
Step 1: Ask yourself a simple question: Can you view your page in the browser, or it is showing something weird?
- If you can view the content, then you can dig further into 2xx codes and 3xx codes.
- If you can't view the content, you can investigate further into 4xx codes and 5xx codes.
Step 2: Open Chrome developer console > network > Reload the page
- Shortcut:Ctrl+Shift+J (on Windows) or Cmd+Option+J (on Mac).
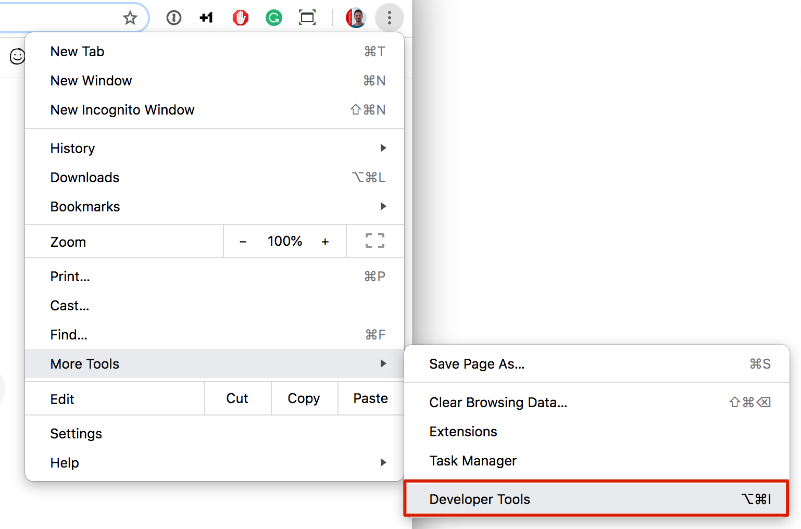
Step 3: Find the page's slug in the "name' column > check "Headers"> check status code.

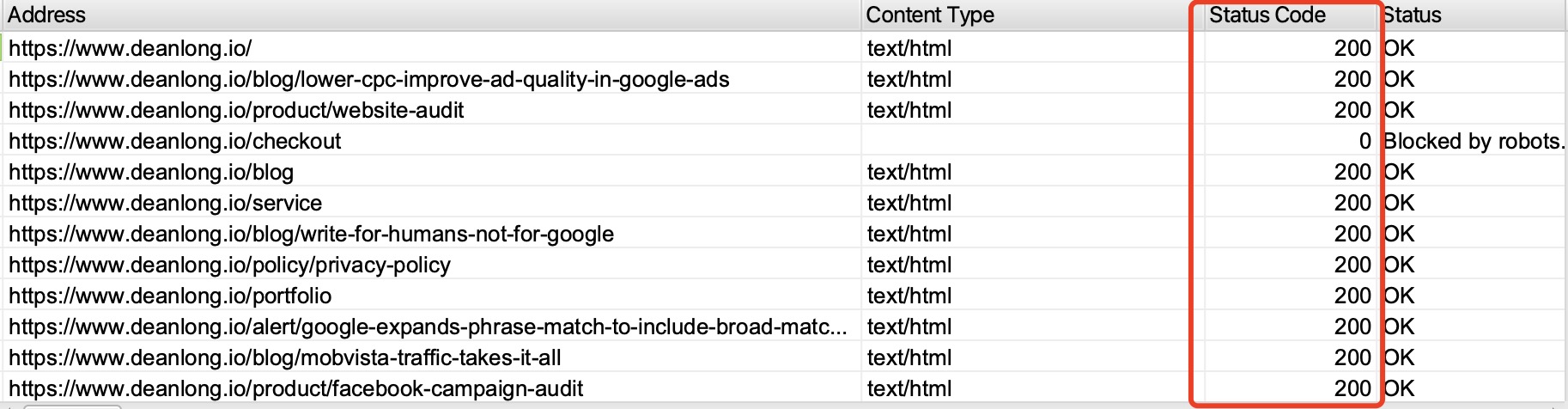
Alternative: Use the screaming frog to crawl your website. The status code is shown in the 'status code' column, while the meaning behind this code is shown in the 'status' column within the default 'Internal' tab view.
How to Address Each HTTP Status Codes?
2xx Status Codes (Success)
These codes indicate that the Google bot crawls the content and queue the content for indexing. However, the following scenarios will show a soft 404 error in the Google search console even if your page returns a 2xx.
- Page load time > Google bot timeout with status code 202
- Empty, blank page with status code 204
- The hero textual content shows an error message (e.g. The page is broken)
Note: An HTTP 2xx status code only indicates an error-free page. It doesn't mean that Google will index your page. What's more interesting, if your page returns a 2xx but shows "crawled, currently not indexed" in the inspection tool on Google Search Console. It might be a sign of a quality issue with your site, implied. (I will attach John Mueller's tweet below)
Here is a table view for the 2xx status code (Source: Google)
3xx Status Codes (Redirects)
Some key takeaways below:
- The 301 redirect is a strong signal that the redirect target should be canonical. Same as 308.
- The 302 redirect is a weak signal that the redirect target should be canonical. Same as 307.
Now you know your way with redirection - 302 won't be interpreted as 301 by Google bot.
- 10 is the maximum times a Google bot can take in the redirection chain. 5 for robot.txt file. But, to be frank, you should keep it under 3 for the sake of your crawl budget. (In Google, it says "ideally no more than 3 and fewer than 5.")
- A 304 status code signals to Google that the content is the same as last time it was crawled. It has no effect on indexing. You may encounter this status code when you refresh an AMP page.
Google makes it clear that not every redirect is the same. For example, Google interprets 308 as the same as 301, but it doesn't mean other search engines tend to do so. Choose the proper server response that is suitable for the page status. What's more, Gary Illyes from Google said the “concrete answer” after he dug into how Google Search handles it internally, is to leave your redirect up for “at least one year.” This will result in Google to pass any signals from the origin URL to the destination URL from the time Google found the redirect.
Here is a table view for the 3xx status code (Source: Google)
4xx Status Codes (Client Errors)
The 4xx status codes mean the spider's request to view the URL is denied by the server. One of the reasons can be the server is overload and not able to process the request.
Dig further: Is the status code the same in other tools (Websniffer, Rexswain, browser plugins etc.).
Some key takeaways below:
- If your page returns 4xx before the indexing, Google will not take this page into the indexing queue.
- If your page is indexed but returns a 4xx code afterwards, Google will lower the crawling frequency, then take it out of the index if there's no sign of reinstation.
- 429 indicates there are too many requests that have been made of the server in a set period. When your server slows down, Google bot tend to have a cup of tea & slow down too. (Learn how to tell Google to index your page faster)
Here is a table view for the 4xx status code (Source: Google)
4xx (client errors) |
Google's indexing pipeline doesn't consider URLs that return a
|
|||||||||
|---|---|---|---|---|---|---|---|---|---|---|
400 (bad request) |
All
The indexing pipeline removes the URL from the index if it was previously indexed.
Newly encountered |
|||||||||
401 (unauthorized) |
||||||||||
403 (forbidden) |
||||||||||
404 (not found) |
||||||||||
410 (gone) |
||||||||||
411 (length required) |
||||||||||
429 (too many requests) |
Googlebot treats the |
|||||||||
5xx (server errors) |
|
Note: Don't use 401 and 403 status codes for limiting the crawl rate. The 4xx status codes, except 429, have no effect on the crawl rate. Instead, learn how to restrict your crawl rate below.
5xx Status Codes (Server Errors)
Similar to code 429, what will happen when the page returns a 5xx code? Again, the Google bot will slow down the crawling. What's worse? Google will remove your page from the index within days if 5xx persists.
Note: Google will use the last cached copy of your robot.txt file if it can't fetch it from your site for more than 30 days. If unavailable, Google assumes that there are no crawl restrictions.
Here is a table view for the 5xx status code (Source: Google)
How To Manage Google Bot's Crawl Rate
Definition: The term crawl rate means how many requests per second Googlebot makes to your site when crawling it: for example, 5 requests per second.
Step 1: Be aware. You cannot change the crawl rate for sites that are not at the root level—for example, www.example.com/folder.
Step 2: Go to Crawl Rate Settings page > Choose your property > select the option you want and then limit the crawl rate as desired. The new crawl rate will be valid for 90 days.
Step 3: Check emergency crawl limitation if the search engine bots are heavily loaded and you need some urgent relief.
Check here if you want to learn how to make Google crawl your page faster!
Contact Your Server Provider (Or Your Server Team)
Network and DNS errors have immediate, adverse effects on a URL's presence in Google Search. Googlebot treats network timeouts, connection reset, and DNS errors similarly to 5xx server errors. In case of network errors, crawling immediately starts slowing down, as a network error is a sign that the server may not handle the serving load. But it will take 2-3 days for Google bot to adapt to the new slower crawl rate. In addition, search Console may generate errors for each respective error.
- Look at your firewall settings and logs. There may be an overly broad blocking rule set.
- Look at the network traffic. Use tools like tcpdump and Wireshark to capture and analyze TCP packets and look for anomalies that point to a specific network component or server module.
- If you can't find anything suspicious, contact your server team.
Debug DNS errors
Google gives detailed instructions about how to debug DNS errors.
Bonus Learning: Understanding HTTP Request Headers and Their Impact on SEO
While HTTP status codes provide insights into the server's response to a specific request, HTTP request headers offer a deeper dive into the communication between the client and the server. These headers play a crucial role in the handshake process and can significantly impact SEO. Let's explore the most important HTTP request headers and understand their significance for SEO analysis.

, source: wizardzines.com from Julia Evans
How Headers Impact SEO:
- Optimised Content Delivery: Headers like User-Agent and Accept ensure that content is tailored and delivered optimally for the client's browser or device. This enhances user experience, a key factor for SEO.
- Improved Page Load Speeds: Headers such as Accept-Encoding and Cache-Control play a role in content compression and caching, directly influencing page load speeds—a vital SEO metric.
- Security and Access Control: The Authorization header ensures that only authenticated users access specific content, safeguarding sensitive information.
- Traffic Source Analysis: The Referer header can be instrumental in backlink analysis, helping in understanding and improving link profiles.
- Avoiding SEO Pitfalls: Misuse of headers, like sending misleading User-Agent strings, can lead to penalties for cloaking.
In conclusion, while HTTP status codes offer a glimpse into server responses, HTTP request headers provide a comprehensive view of the client-server communication. By understanding and optimizing these headers, one can significantly enhance their SEO strategy, ensuring that content is not only accessible but also optimised for the end-user.
Related Article:
Learn How To Get Google to Index Your Page Sooner & Faster
References:
- https://searchengineland.com/google-publishes-seo-guide-to-http-status-codes-network-and-dns-errors-349928
- https://developers.google.com/search/docs/advanced/crawling/http-network-errors
- https://developers.google.com/search/docs/advanced/crawling/site-move-with-url-changes
- https://support.google.com/webmasters/answer/48620
- https://www.screamingfrog.co.uk/http-status-codes-when-crawling/
- https://developer.mozilla.org/en-US/docs/Web/HTTP/Status
- https://www.searchenginejournal.com/what-is-http2/410586/
- https://wizardzines.com/comics/request-headers/




Related Posts
